
代码很少,却很优秀!RocketMQ的NameServer做到了!
你好,我是猿java。
今天我们来一起深入分析 RocketMQ的注册中心 NameServer。
本文基于 RocketMQ release-5.2.0
首先,我们回顾下 RocketMQ的内核原理鸟瞰图:
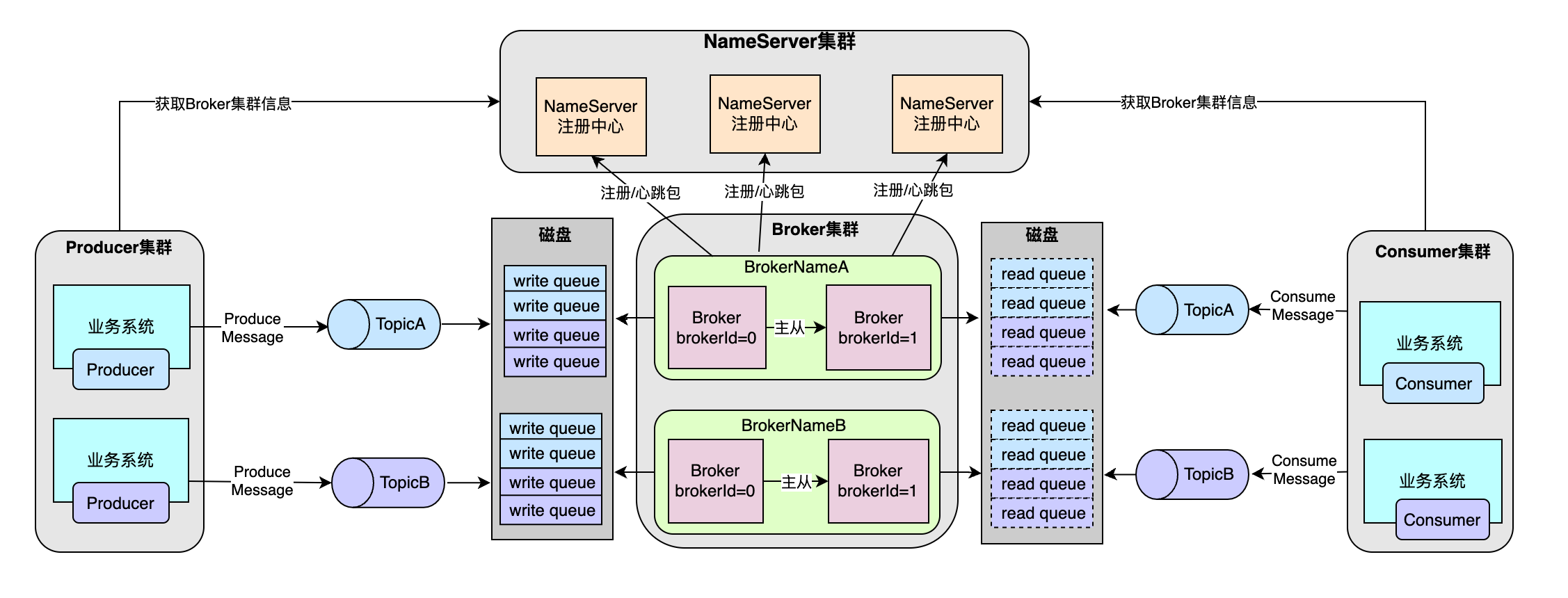
从上面的鸟瞰图,我们可以看出:Nameserver即和 Broker交互,也和 Producer和 Consumer交互,因此,在 RocketMQ中,Nameserver起到了一个纽带性的作用。
接着,我们再看看 NameServer的工程结构,如下图:
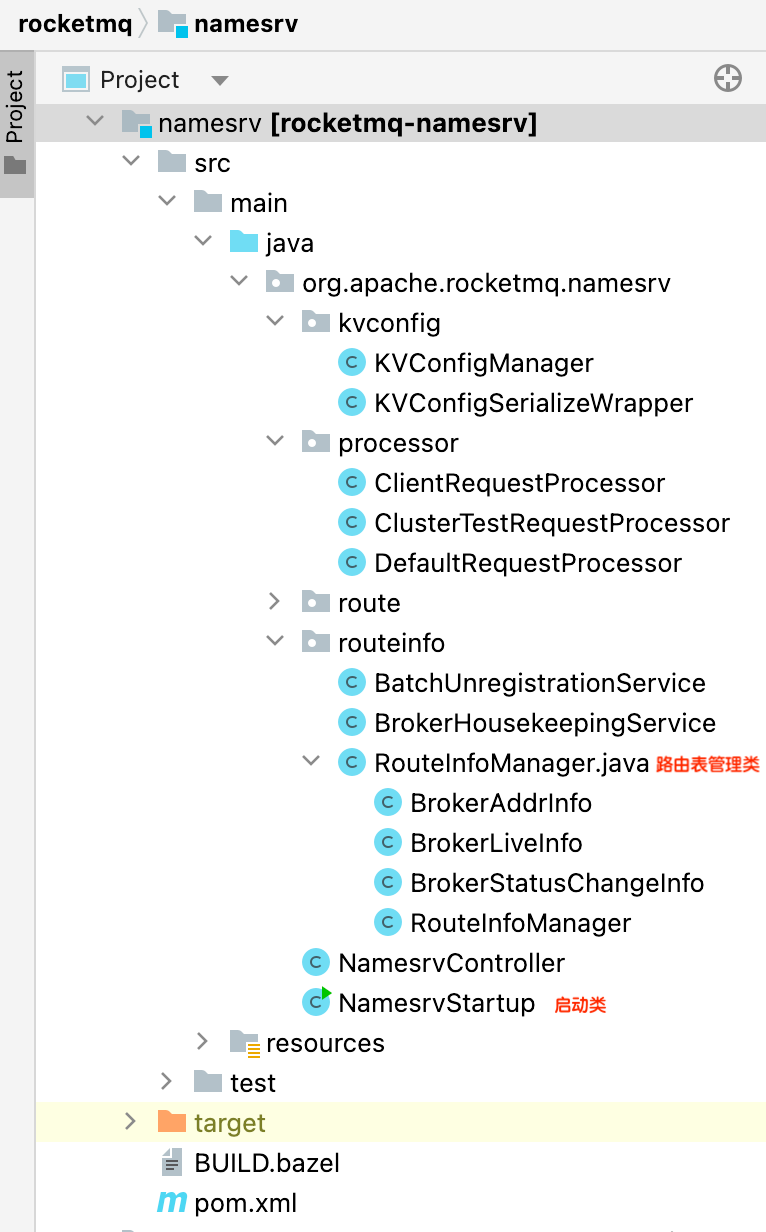
整个工程只有 11个类(老版本好像只有不到 10个类),为什么 RocketMQ可以用如此少的 Class类,设计出如此高性能且轻量的注册中心?
我觉得最核心的有 3点是:
AP设计思想- 简单的数据结构
- 心跳机制
AP设计思想
像 ZooKeeper,采用了 Zab (Zookeeper Atomic Broadcast) 这种比较重的协议,必须大多数节点(过半数)可用,才能确保了数据的一致性和高可用,大大增加了网络开销和复杂度。
而 NameServer遵守了 CAP理论中 AP,在一个 NameServer集群中,NameServer节点之间是P2P(Peer to Peer)的对等关系,并且 NameServer之间并没有通信,减少很多不必要的网络开销,即便只剩一个 NameServer节点也能继续工作,足以保证高可用。
数据结构
NameServer维护了一套比较简单的数据结构,内部维护了一个路由表,该路由表包含以下几个核心元数据,对应的源码类RouteInfoManager如下:
1 | public class RouteInfoManager { |
- topicQueueTable: Topic消息队列路由信息,消息发送时根据路由表进行负载均衡
- brokerAddrTable: Broker基础信息,包括brokerName、所属集群名称、主备Broker地址
- clusterAddrTable: Broker集群信息,存储集群中所有Broker名称
- brokerLiveTable: Broker状态信息,NameServer每次收到心跳包是会替换该信息
- filterServerTable: Broker上的FilterServer列表,用于过滤标签(Tag)或 SQL表达式,以减轻 Consumer的负担,提高消息消费的效率。
TopicRouteData
TopicRouteData是 NameServer中最重要的数据结构之一,它包括了 Topic对应的所有 Broker信息以及每个 Broker上的队列信息,filter服务器列表,其源码如下:
1 | public class TopicRouteData { |
BrokerData
BrokerData包含了 Broker的基本属性,状态,所在集群以及 Broker服务器的 IP地址,其源码如下:
1 | public class BrokerData { |
QueueData
QueueData包含了 BrokerName,readQueue的数量,writeQueue的数量等信息,对应的源码类是QueueData,其源码如下:
1 | public class QueueData { |
元数据举例
为了更好地理解元数据,这里对每一种元数据都给出一个数据实例:
1 | topicQueueTable:{ |
1 | brokeAddrTable:{ |
1 | brokerLiveTable:{ |
1 | clusterAddrTable:{ |
1 | filterServerTable:{ |
心跳机制
心跳机制是 NameServer维护 Broker的路由信息最重要的一个抓手,主要分为接收心跳、处理心跳、心跳超时 3部分:
接收心跳
Broker每 30s会向所有的 NameServer发送心跳包,告诉它们自己还存活着,从而更新自己在 NameServer的状态,整体交互如下图: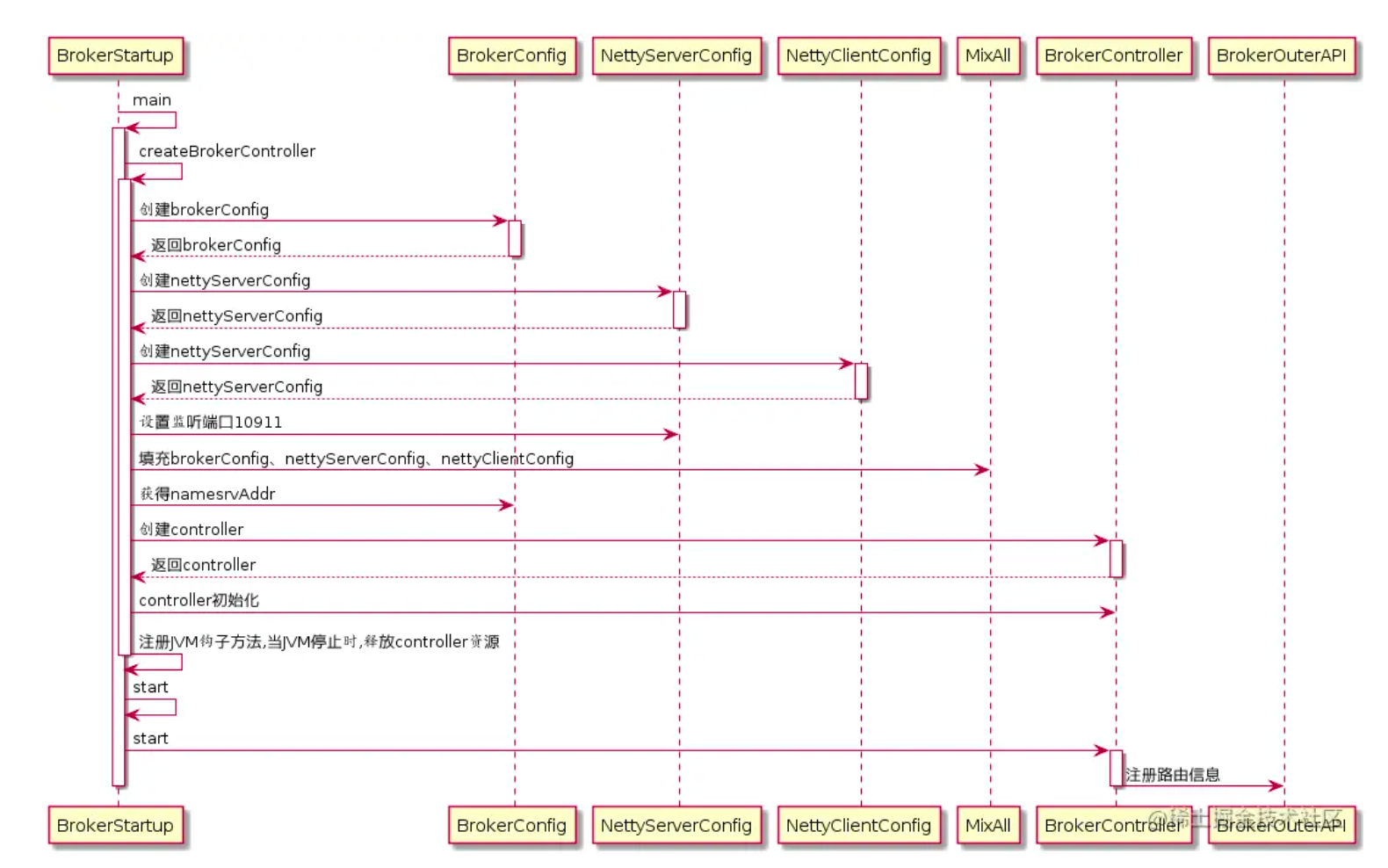
处理心跳
NameServer收到心跳包时会更新 brokerLiveTable缓存中 BrokerLiveInfo的 lastUpdateTimeStamp信息,整体交互如下图:
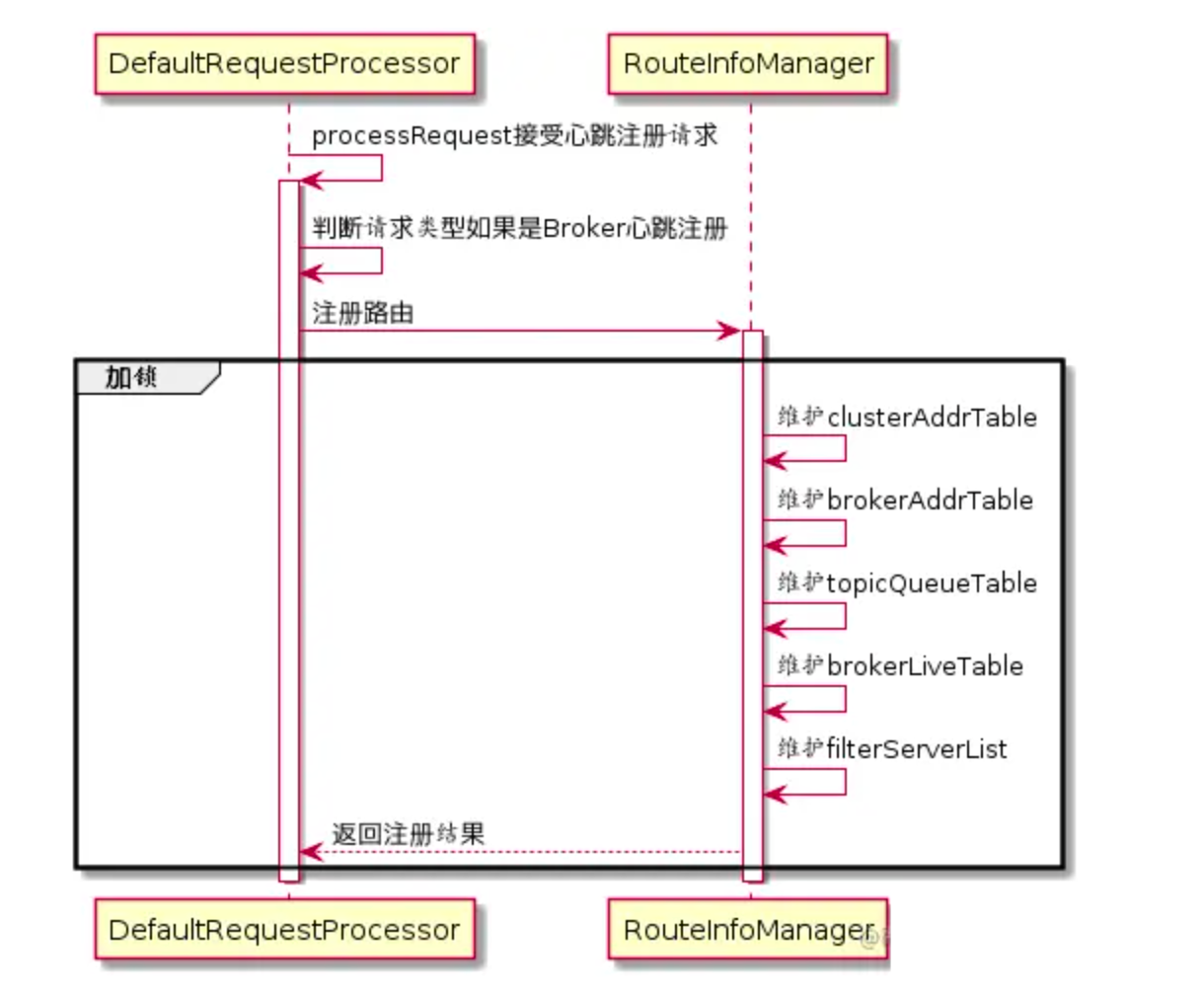
处理逻辑可以参考源码:org.apache.rocketmq.namesrv.processor.DefaultRequestProcessor#processRequest#brokerHeartbeat:
1 | public RemotingCommand brokerHeartbeat(ChannelHandlerContext ctx, |
心跳超时
NameServer每隔 10s(每隔5s + 5s延迟)扫描 brokerLiveTable检查 Broker的状态,如果在 120s内未收到 Broker心跳,则认为 Broker异常,会从路由表将该 Broker摘除并关闭 Socket连接,同时还会更新路由表的其他信息,整体交互如下图:
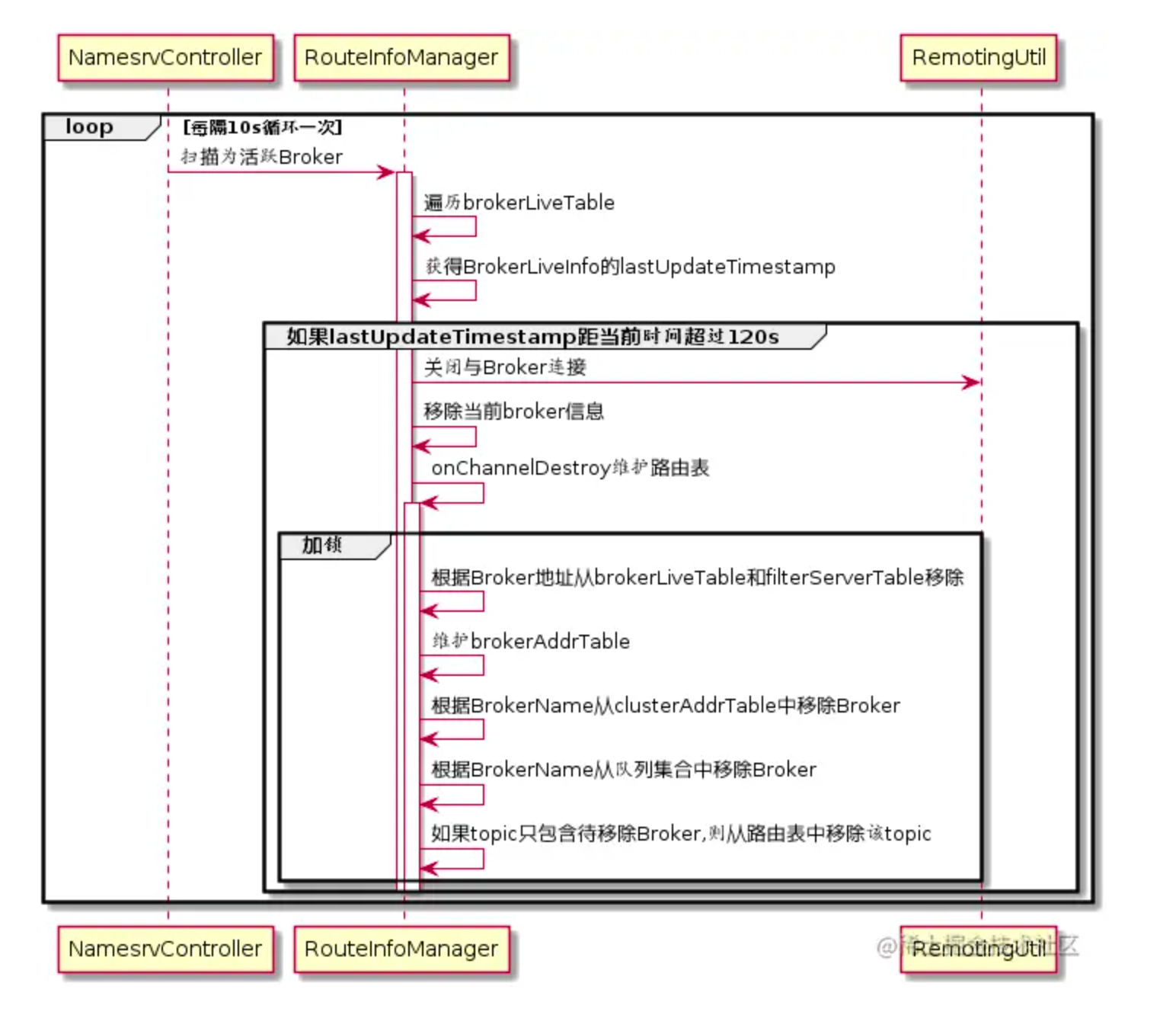
1 | private void startScheduleService() { |
源码参考:org.apache.rocketmq.namesrv.routeinfo.RouteInfoManager#unRegisterBroker(),核心流程:
- 遍历brokerAddrTable
- 遍历broker地址
- 根据 broker地址移除 brokerAddr
- 如果当前 Topic只包含待移除的 Broker,则移除该 Topic
其他核心源码解读
NameServer启动
NameServer的启动类为:org.apache.rocketmq.namesrv.NamesrvStartup,整个流程如下图:
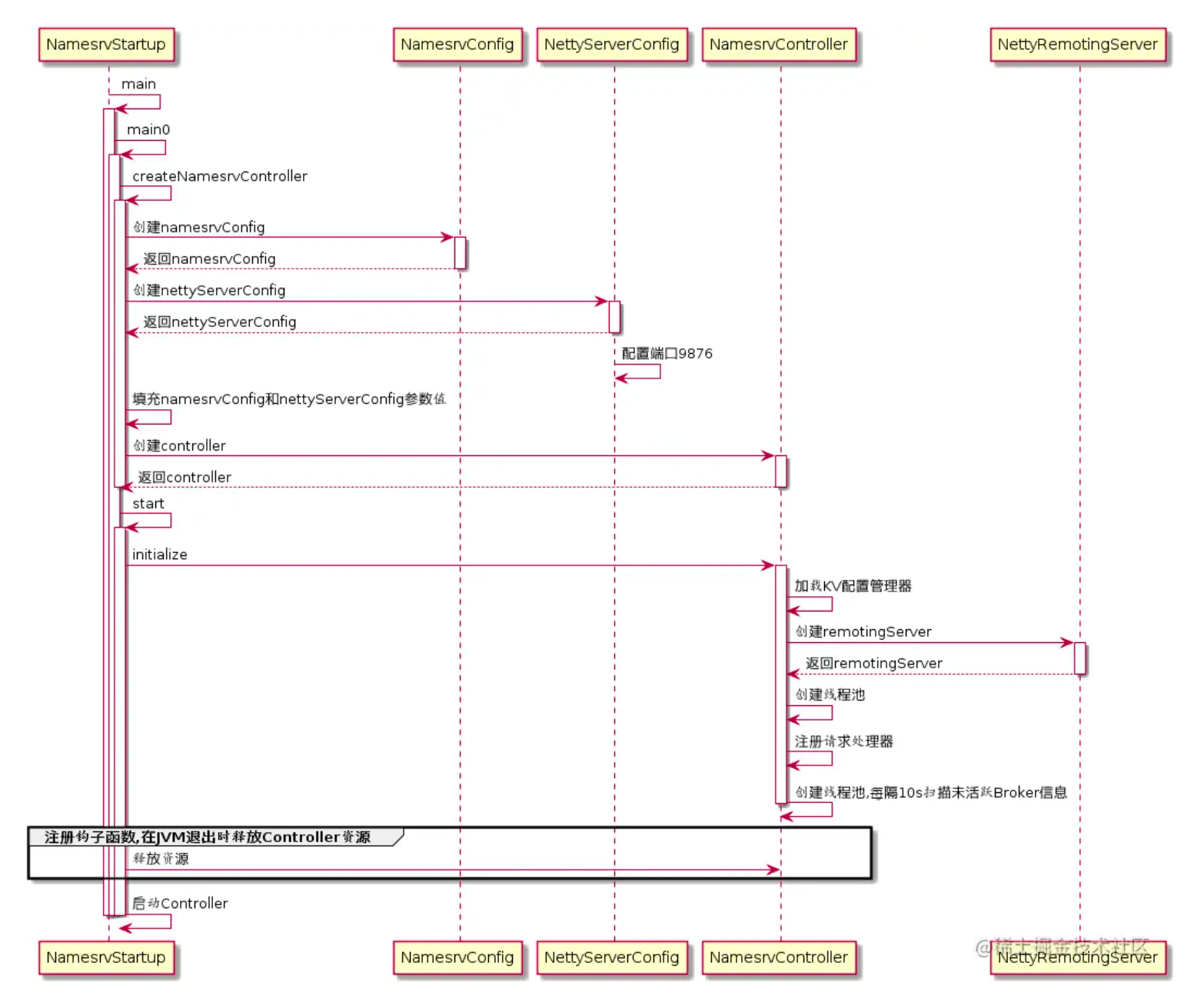
NameServer启动最核心的 3个事情是:
- 加载配置:NameServerConfig、NettyServerConfig主要是映射配置文件,并创建 NamesrvController。
- 启动 Netty通信服务:NettyRemotingServer是 NameServer和Broker,Producer,Consumer通信的底层通道 Netty服务器。
- 启动定时器和钩子程序:NameServerController实例一方面处理 Netty接收到消息后,一方面内部有多个定时器和钩子程序,它是 NameServer的核心控制器。
总结
NameServer并没有采用复杂的分布式协议来保持数据的一致性,而是采用 CAP理论中的 AP,各个节点之间是Peer to Peer的对等关系,数据的一致性通过心跳机制,定时器,延时感知来完成。
NameServer最核心的 3点设计是:
AP的设计思想- 简单的数据结构
- 心跳机制
学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
