
AI的核心原理是什么?如何搭建一个AI聊天机器人?
嗨,你好呀,我是猿java
AI无疑是当下最热门的一个话题,不管你是不是做技术,多多少少都听过它,很多人甚至都担心自己的工作会被它取代,那么,AI的背后的原理是什么?为什么它会这么流行?这篇文章,我们通过搭建一个简单的聊天机器人来了解 AI背后的秘密。
1. 实现机器人的方式
实现的机器人的方式很多,这里我们列举三类常见的实现方式:
1.1 预设答案
预设答案是指我们可以预设一些问题,然后给每个问题预先设置好答案,对于没有预先设置好的问题,统一使用默认答案。比如公众号里面的自动回复功能,如下图:
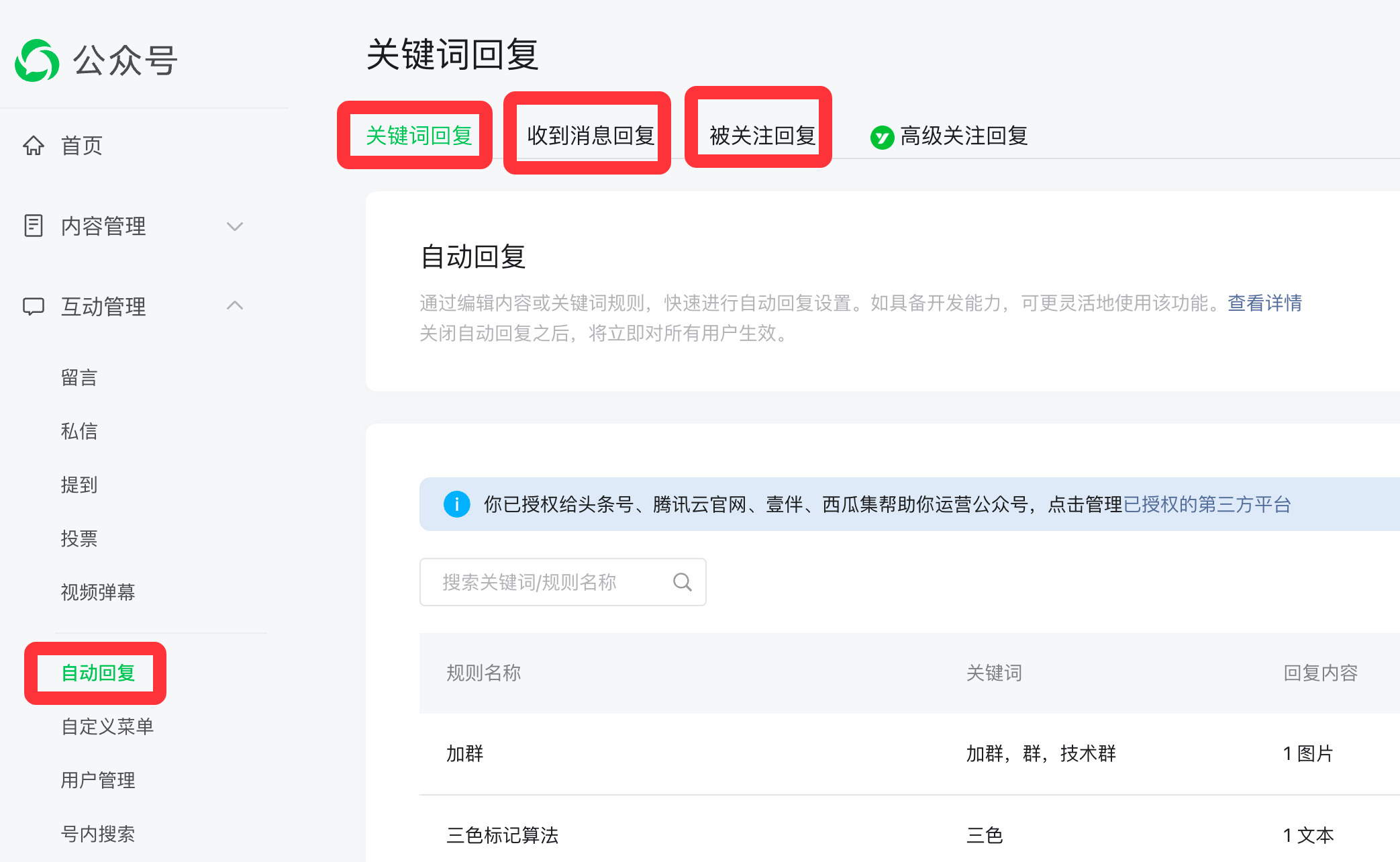
预设答案是最简单且最安全的一种实现方式,最简单是因为它完全没有什么技术含量,完全是一个关键字Map的机制。最安全是因为答案是预先配置好,完全可控,所以不管提问者提什么样的问题,都不可能有涉政,涉黄,涉暴的问题。
1.2 常规算法
基于常规算法是指,根据用户的输入,需要分析其语义,然后作出合理的回答,常见的算法有决策树、线性回归等。
决策树是一种用于分类和回归的非参数模型,其基本思想是将数据集划分为更小的子集,同时构建一个类似树结构的决策模型。这个树由节点(Node)和分支(Branch)组成:
- 根节点(Root Node) :数据开始的地方,包含整个数据集。
- 内部节点(Internal Nodes) :根据某个特征进行数据的条件判断分割。
- 叶子节点(Leaf Nodes) :代表最终的决策结果或类别。
线性回归是一种统计方法,用于建模目标变量和一个或多个自变量之间的线性关系。其目标是找到一个线性方程,使得预测值和实际值之间的误差最小化。
1.3 大语言模型
大型语言模型(Large Language Models,LLMs)是非常大的深度学习模型,预先在海量数据上进行训练,其底层的 Transformer(在 2017年由谷歌在论文“Attention Is All You Need”中首次提出)是一组神经网络,包括具有自注意力能力的编码器和解码器。编码器和解码器从文本序列中提取意义,并理解其中单词和短语之间的关系。
LLMs是目前最为流行的一种方式,比如字节的豆包,Facebook的Chatbot,如 OpenAI 的 GPT-3、GPT-4、ChatGPT-4o,谷歌的 BERT 和 T5 等。下面是我和豆包的一段对话:

豆包MarsCode可以根据我的问题,分析我的语义,给出相当 nice的答案,给国产的ChatGPT点赞。
LLMs核心是 Transformer神经网络架构允许使用非常大的模型,通常具有数千亿个参数。这种大规模的模型可以摄取海量数据,通常来自互联网,也包括像 Common Crawl这样的来源,后者包括超过 500亿个网页,以及维基百科,大约有 5700万页。
Transformer模型工作流程如下图:
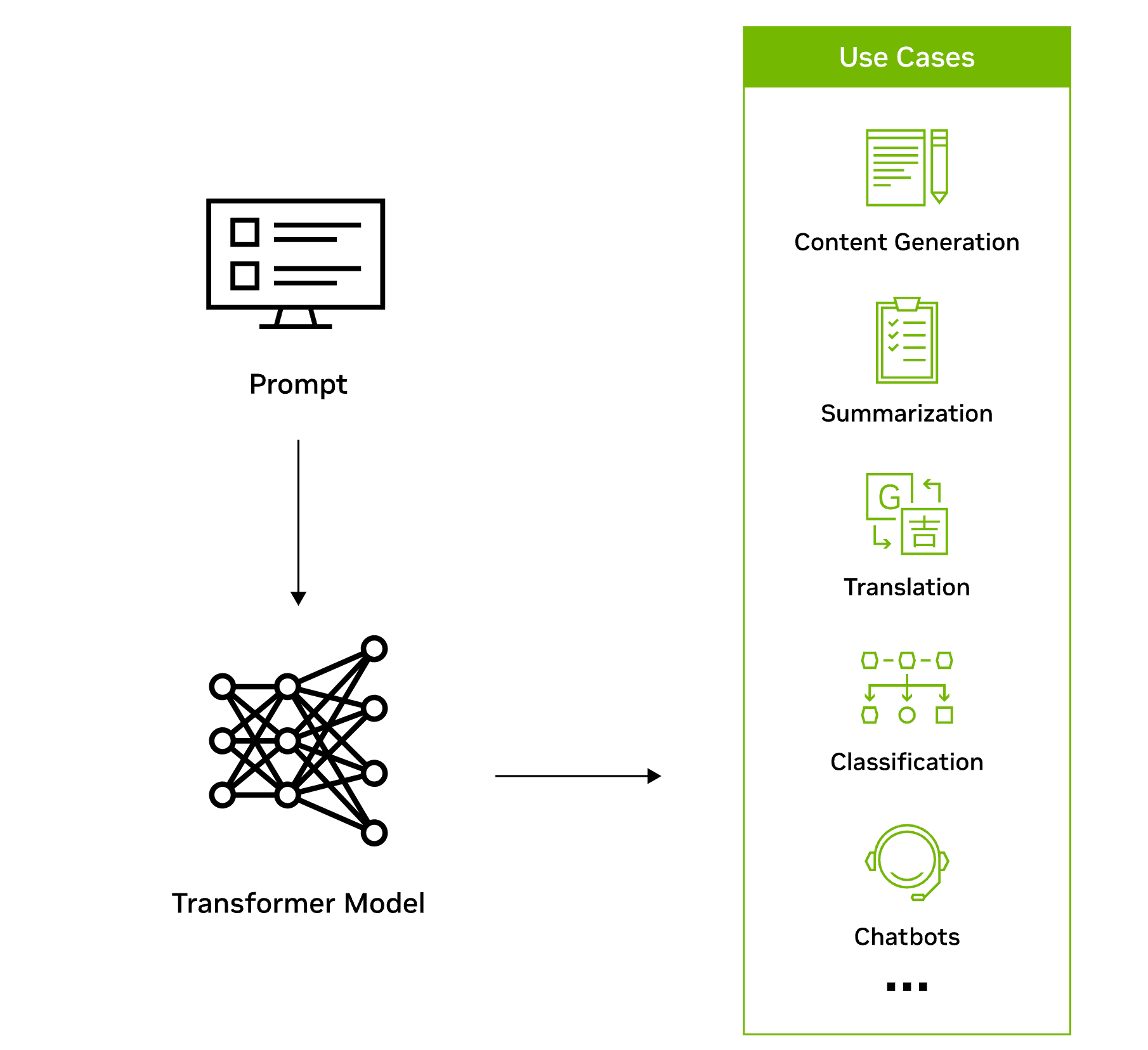
Transformer之所以非常适合用于大型语言模型,主要有两个关键创新:位置编码和自注意力。
位置编码(positional encodings):是指嵌入输入在序列中出现的顺序。本质上,借助位置编码,单词可以不按顺序输入到神经网络中,而不是逐个按顺序输入。
自注意力(self-attention):在处理输入数据时为每个部分分配一个权重,这个权重表示该输入在整个输入中的重要性。换句话说,模型不需要对所有输入给予同等的注意,而是可以专注于实际上重要的部分。随着模型筛选和分析海量数据,这种关于神经网络需要关注的输入部分的表示会逐渐学习。
这两种技术结合在一起,使得可以分析在长距离、非顺序的情况下,各个元素是如何微妙地影响和相互关联的。这种非顺序处理数据的能力能够把复杂问题分解成多个小的、同时进行的计算。自然地,GPU在并行解决这些类型的问题上非常适合,可以大规模处理大型未标注数据集和巨大的Transformer网络。
因为 LLMs的知识点太多,更多关于 LLMs的原理,可以参考我前面的文章:AI背后的”思考者”:LLM大语言模型是什么?
2. 如何搭建聊天机器人?
2.1 目标
设计一个聊天机器人,能理解用户的输入并提供合理的答复。
2.2 技术栈
- Java: 使用Java作为开发语言。
- Spring Boot: 作为项目的基础框架,用于快速构建和部署 RESTful应用程序。
- Spring AI: 使用 Spring Boot与AI API服务集成。
- RESTful API: 提供 HTTP接口以与聊天机器人进行交互。
- OpenAI API: 使用 OpenAI的 GPT等模型来处理自然语言并生成回复。
2.3 项目结构
- Controller: 处理 HTTP请求。
- Service: 业务逻辑层,包括与 OpenAI API的交互。
- Model: 定义请求和响应的数据结构。
- Configuration: 配置 OpenAI API的访问。
2.3 步骤详解
1. 开始一个Spring Boot项目
首先,我们在开发环境中创建一个新的 Spring Boot项目,包括以下依赖:
- Spring Web
- Spring Boot DevTools
- Spring Configuration Processor
2. 配置OpenAI API
在application.properties或application.yml文件中,配置 OpenAI API key,例如:
1 | openai.api.key=YOUR_OPENAI_API_KEY |
需要从 OpenAI平台申请一个 API key。
3. 实现Controller
接下来,实现一个简单的 RESTful控制器来处理客户端请求,创建一个名为ChatController的类。
1 |
|
在这里,ChatRequest是一个包含用户输入消息的模型,而ChatResponse是包含聊天机器人的回复模型。
4. 定义Model层
创建请求和响应的模型类。
1 | public class ChatRequest { |
5. 创建Service
建立一个ChatService类,通过此类调用 OpenAI API。
1 |
|
在getResponse方法中,实现与 OpenAI API的交互。这包括设置HTTP请求头,发送用户消息,并解析API返回的回复。
6. 配置API客户端
使用Spring配置管理API客户端的细节。也可以使用HttpClient或RestTemplate等工具来进行HTTP请求。
1 |
|
7. 与OpenAI API交互
在实际应用中,这一步可能涉及到复杂的API调用和响应处理,以下是一个简单的示例,展示如何使用 RestTemplate与OpenAI API交互。
1 | private String callOpenAIAPI(String message) { |
到此,一个简单的聊天机器人就实现好了,其实依赖 OpenAI的API实现聊天机器人很简单,因为核心的语义分析等技术难点已自包含在三方 API中,我们只需要关注自己的业务逻辑。
3. 总结
本文,我们分析了几种实现聊天机器人的方法,从传统的方式到如今如日中天的大语言模型, 然后基于 Spring Boot 和 OpenAI的 API,实现了一个简易的聊天机器人,搭建的过程很简单。
作为一名技术人员,或许你不是从事 AI相关的工作,但是,怀着对技术的好奇心,我们不应该只停留在使用 AI的阶段,而更应该去了解 AI,了解 LLMs的原理,了解 Transformer模型,了解它和 CNNs和 RNNs的区别,从而更加好地扩展我们的技术视野。
对于一些国产的 AI产品,我们应该采用包容的态度多去使用它们,比如我们的豆包,让 AI真正可以为我们的技术赋能。
因为大语言模型的知识点实在是太多了,所以本文很难用文字完全描述。作为一名Java猿,我自己也一直在学习LLMs,我相信技术不应该被我们当前使用的语言所束缚,而应该不断地拓展视野,只要能坚持学习积累,或许有一天我们也可以在 AI的大浪中乘风破浪。
4. 交流学习
最后,把猿哥的座右铭送给你:投资自己才是最大的财富。 如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
