
Gossip协议如何保证 Redis数据的一致性?
Hello,Hi,你好,我是猿java。
今天我们分享的内容是:GGossip协议如何保证 Redis数据的一致性。
声明:本文基于 Redis 7.0 版本
提起 Redis,应该说是 NO SQL数据库的天花板了,作为一名 Java工程师应该并不陌生,那么,Redis 是如何保证集群节点间数据的一致性呢?今天就来聊一聊。
在开始今天的内容之前,需要先对 Gossip协议以及工作原理做一个详细的分析。
1. Gossip 定义
Gossip:中文翻译有流言蜚语,闲话,八卦等含义。
Gossip协议的原型是 Xerox 公司的Palo Alto 研究中心在 EPIDEMIC ALGORITHMS FOR REPLICATED DATABASE MAINTENANCE 论文中提出的,
在论文中称该算法为 Epidemic Algorithm(八卦算法 或 病毒算法),不过,Epidemic Algorithm 普遍被大家认识的还是 Gossip 这个名字。Gossip协议是一种在分布式系统中共享状态的去中心化协议,用来实现多个节点之间信息交换。
Gossip协议一个最典型的使用案例是比特币,在比特币网络中,使用 Gossip协议来同步各个节点区块头和区块体的信息。
Xerox,全称 Xerox Holdings Corporation,是一家美国公司,主要是销售印刷和数字文档产品和服务,该公司的Palo Alto研究中心在计算机技术领域还扮演了重要角色,比如:图形界面的发明者、以太网的发明者、激光打印机的发明者、MVC 架构的提出者、RPC 的提出者、BMP 格式的提出者等等。
2. Gossip 原理
通读了论文《EPIDEMIC ALGORITHMS FOR REPLICATED DATABASE MAINTENANCE》,小编总结出了论文的核心内容:Gossip协议主要是通过 Direct Mail、Anti-entropy 和 Rumor mongering 3种方式来实现数据的最终一致性。接下来,我们将分别解析这 3种方式。
2.1 Direct mail
Direct mail,翻译为直邮,它是指当集群中某个节点有数据更新时,会把更新的数据直接发送给其他节点,当数据发送失败时,需要将数据缓存以便重传。直邮方式比较简单,时效性高,但是不完全可靠。
为了更好的说明直邮方式,这里以拥有 节点A、节点B、节点C、节点D、节点E 5个节点的集群为例,当节点A 的数据更新为 a = 2时,会直接将新数据传给其他节点,然后各个节点再更新自己的数据,整个直传过程如下图:
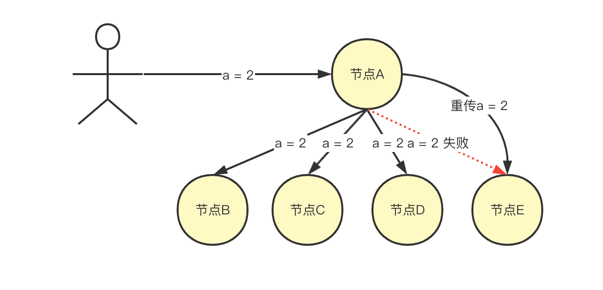
需要说明的是:当队列溢出或长时间无法访问其目的地时,消息可能会被丢弃,也就是说,只采用直邮的方式是无法实现最终一致性的。
2.2 Anti-entropy
Anti-entropy,翻译为反熵,反熵是热力学中的一个术语,原意是指投入的多但释放出来的能量少,是“费力不讨好”的现象在物理学中表现的一种形式。
在此处,熵可以理解成数据的差异性,反熵就是消除数据的差异。集群中的节点,每隔一段时间(周期性)会随机选择任一节点,然后通过互相交换数据来消除两者之间的差异,实现最终一致性。反熵极其可靠但需要检查数据库的内容,因此速度会比直邮方式慢。
实现反熵主要有push、pull 和 push-pull 3种方式:
push 推方式
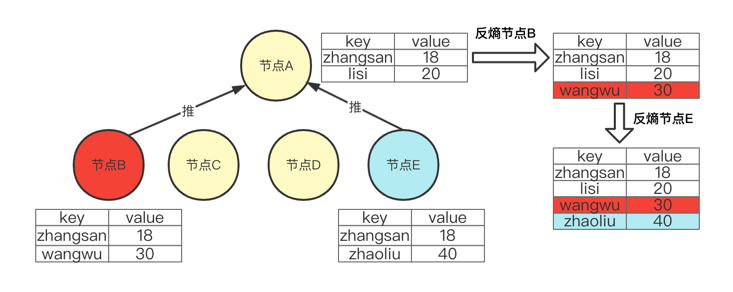
push 就是将自己的所有数据副本推送给对方,让对方修复数据差异。如下图:节点B,节点E 将所有数据推给节点A 进行数据修复,最终,节点A 的数据为 3个节点数据的并集。
pull 拉方式
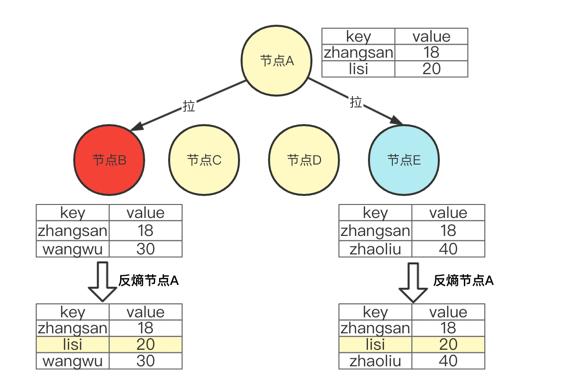
pull 就是拉取对方所有的数据副本,然后修复自己的数据差异。如下图:节点B,节点E 拉取节点A 所有的数据来修复自己,最后节点B 和节点E 都包含了节点A 的所有数据。如此周期性的循环,最终,5个节点的数据就能保持最终一致性。
push-pull 推拉方式
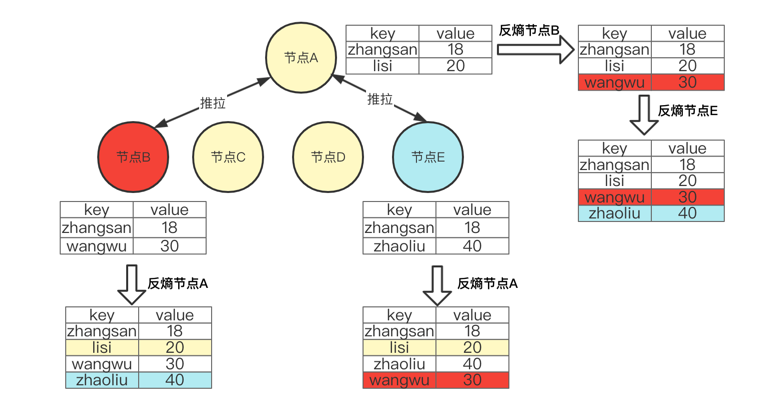
push-pull,是 push 和 pull 的综合,同时修复自己的数据和对方的数据。如下图:节点A,节点B,节点E 通过推拉模式来修复各自的数据,这样 3个节点的数据就保持一致。
通过上述 3种反熵方式可以发现:反熵可以实现最终一致性,但是,节点之间需要相互交换和比较数据,如果集群节点数比较多,代价就成直线上升,因此,反熵方式适合节点数固定且有限的集群实现数据一致性。
2.3 Rumor mongering
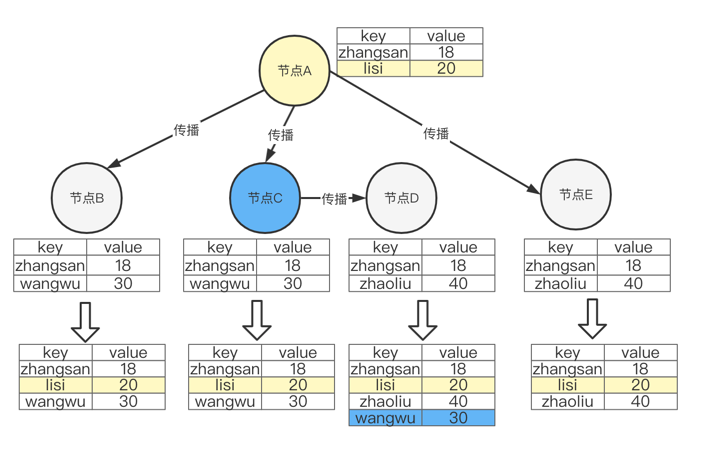
Rumor mongering,翻译为造谣,谣言传播,它是指集群中的某一节点有数据更新时,就会定期选择一个节点向其传播自己的新数据,该节点也会成为活跃节点,再向其他节点传播新数据,因此整个过程就像谣言传播一样。
如下图所示:当节点A 有新数据 lisi:20 时,会成为活跃节点,然后向集群中节点B,节点E 传播该数据,节点C 收到新数据之后也变成了活跃节点,然后向节点D 传播新数据,这样其他节点都能更新到新数据。
到此, Gossip协议的定义及其主要工作原理就分析完成,如果想了解更多细节可以详读论文。接下来的内容是呼应文章标题:Gossip协议如何保证 Redis数据的一致性?
3. Gossip 保证Redis数据的一致性
Redis采用了 Gossip协议的反熵模式,不过 Redis 并没有照搬 Gossip协议,而是改良出一套自己的 PING-PONG方案(类同反熵的 push-pull),实现细节可以参考 Redis源码的 cluster.h 和 cluster.c 2个文件。
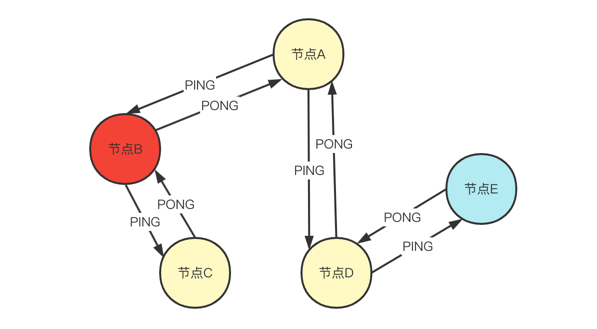
如下图:集群包含 节点A,节点B,节点C,节点D,节点E 5个节点,集群中的每个节点,会按照固定频率,从集群中「随机」挑选部分实例,发送 PING 消息,收到 PING 消息的节点在经过一些处理后会回复 PONG 消息,这样节点间就完成了彼此状态信息的交换,具体的原理会在下面的源码分析中进行解析。
3.1 解决的场景
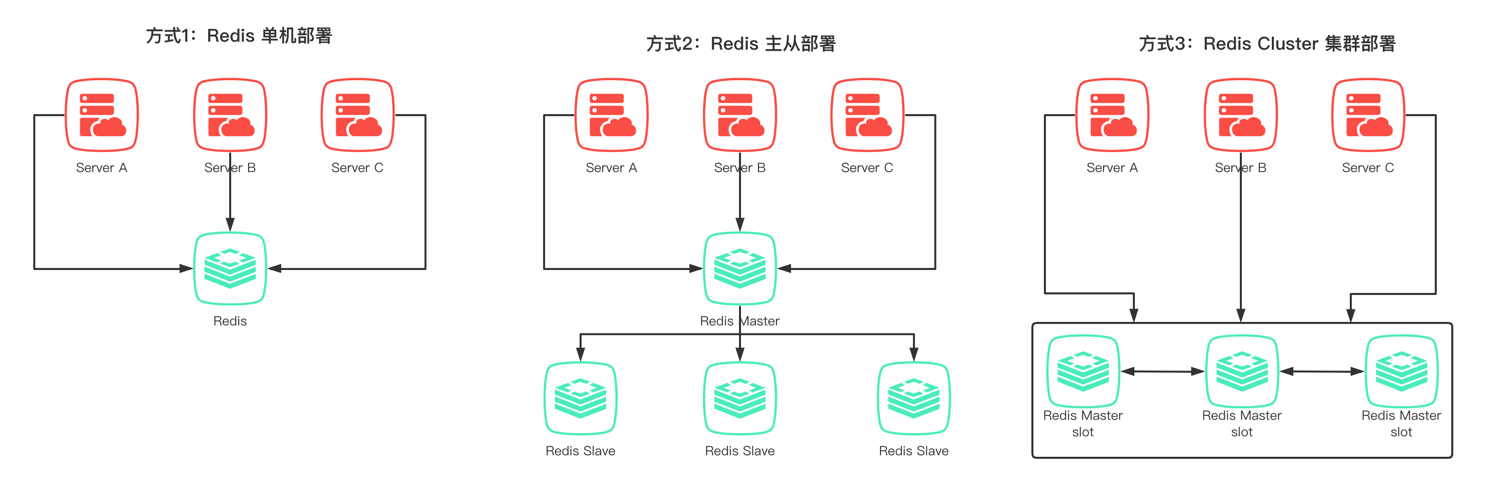
如下图:Redis部署的 3种模式。在 Redis Cluster 集群部署模式下,使用的是 Gossip协议,因此需要声明的是:Gossip协议只能解决 Redis Cluster 部署方式下的数据一致性问题。
3.2 节点通信消息类型
在 Redis源码 cluster.h 文件中,通过宏定义的方式定义了节点间通信的消息类型,如下截图:
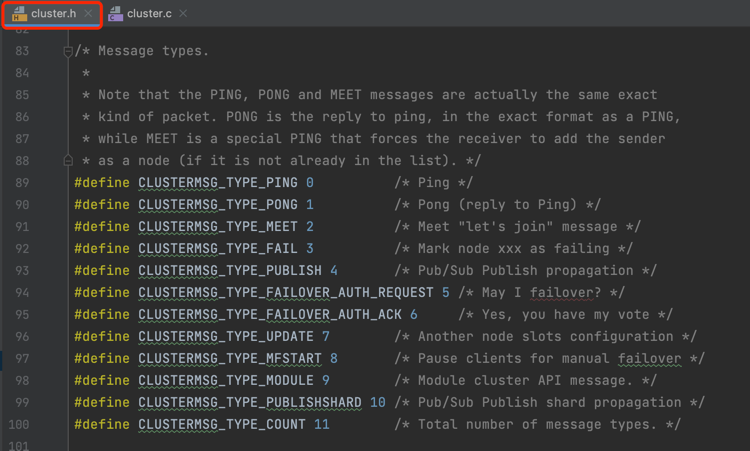
通过上述的源码截图可以看出 Redis Cluster集群节点间通信的消息类型有 12种之多,这里列举了 4种常用的类型:
- CLUSTERMSG_TYPE_PING 0:PING消息,用来向其他节点发送当前节点信息;
- CLUSTERMSG_TYPE_PONG 1:PONG消息,响应 PING消息;
- CLUSTERMSG_TYPE_MEET 2:MEET消息,表示某个节点要加入集群;
- CLUSTERMSG_TYPE_FAIL 3:FAIL消息,表示某个节点有故障 ;
需要注意的是:PING、PONG 和 MEET 消息实际上是完全相同类型的数据包。 PONG 是对 PING 的回复,与 PING 的格式完全相同,而 MEET 是一种特殊的 PING,它强制接收方将发送方添加为节点。
3.3 消息结构体
有了消息类型,我们就可以进一步的分析每种消息类型的消息是如何定义的,在Redis中, 通过 clusterMsg 定义了一个消息结构体,用来表示节点间通信的一条消息,源码截图如下:
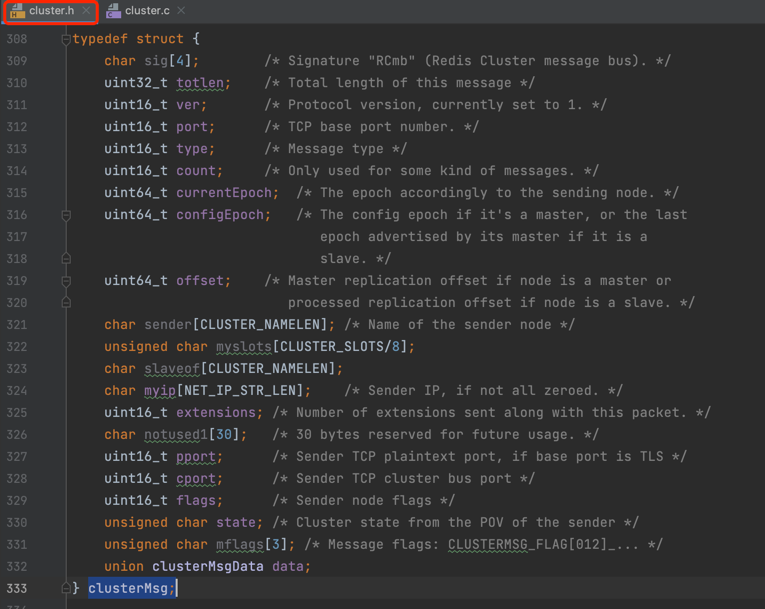
从上述 clusterMsg 源码截图可以看出:clusterMsg 结构体包含了 发送消息节点的名称、发送消息节点的IP、通信端口、负责的 slots、消息类型、消息长度和具体的消息体等信息,其中消息体又是通过 clusterMsgData 来定义的,源码截图如下:
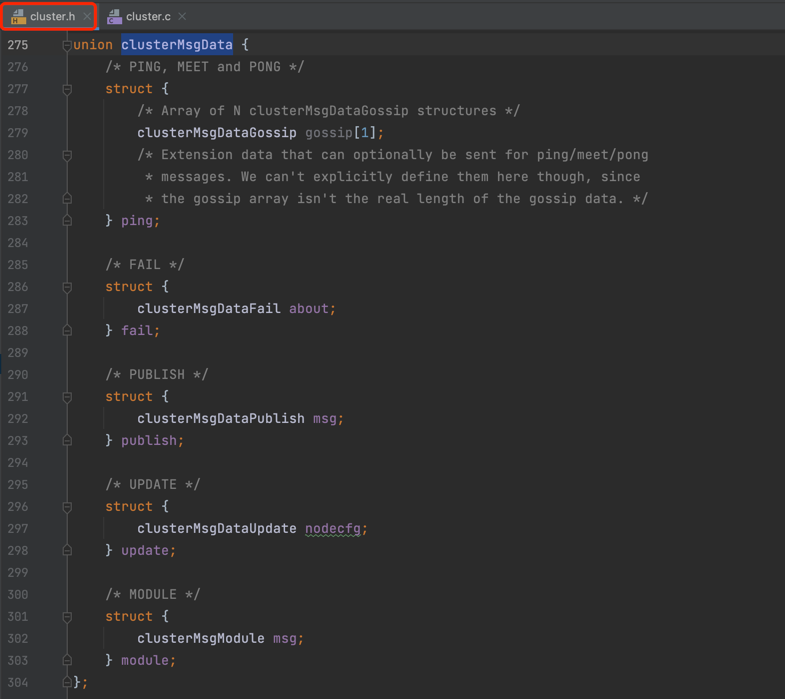
从上述 clusterMsgData 源码截图可以看出:clusterMsgData 包含了 clusterMsgDataGossip、clusterMsgDataFail、clusterMsgDataPublish 和 clusterMsgDataUpdate 等多种消息类型对应的数据结构,而 PING,PONG,MEET类型又是通过 clusterMsgDataGossip来表示的,因此重点看下 clusterMsgDataGossip,源码截图如下:
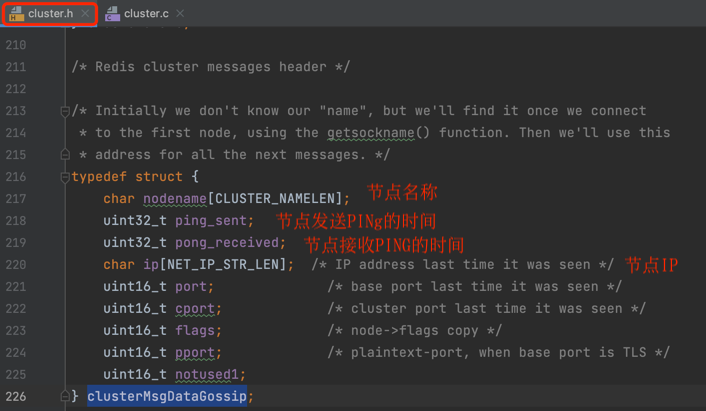
clusterMsgDataGossip 结构体中包含了:节点名称,节点IP,节点发送PING的时间,节点接收PONG消息的时间,节点和客户端的通信端口,节点间通信的端口等信息。
3.4 执行流程
通过上述对 PING,PONG消息的描述,能够清晰知道PING,PONG消息会携带哪些信息,接下来就来分析 PING,PONG是如何交互的。
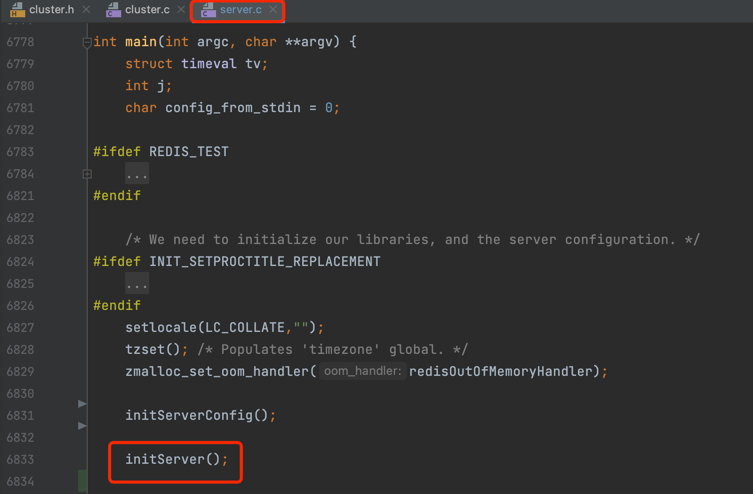
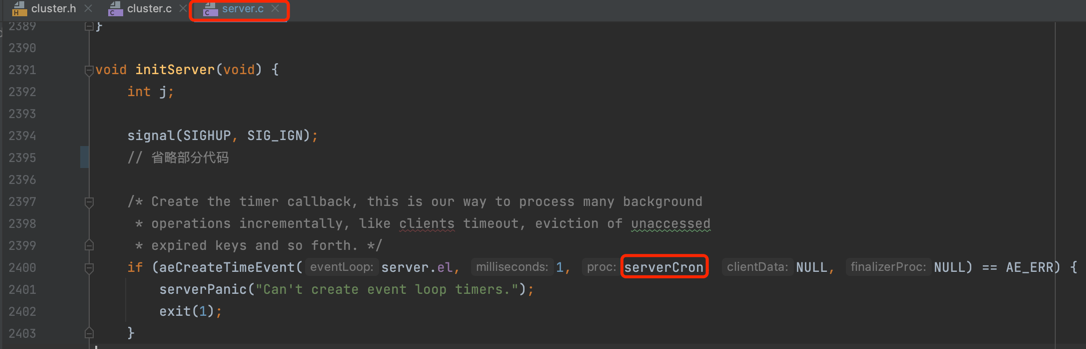
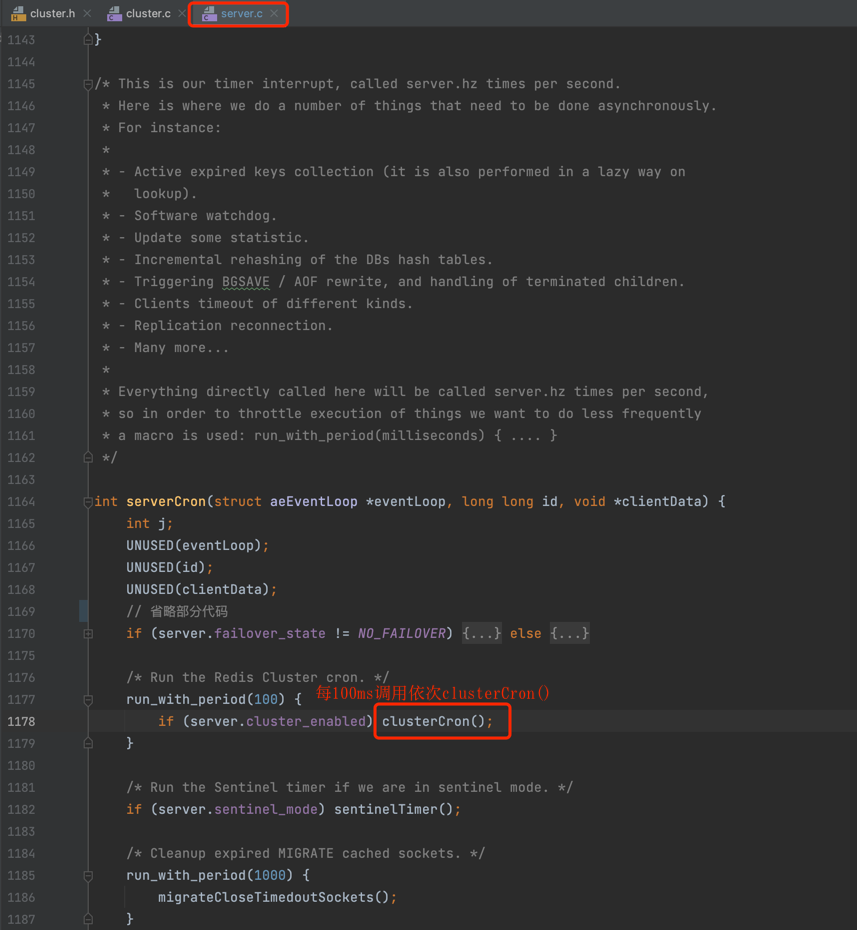
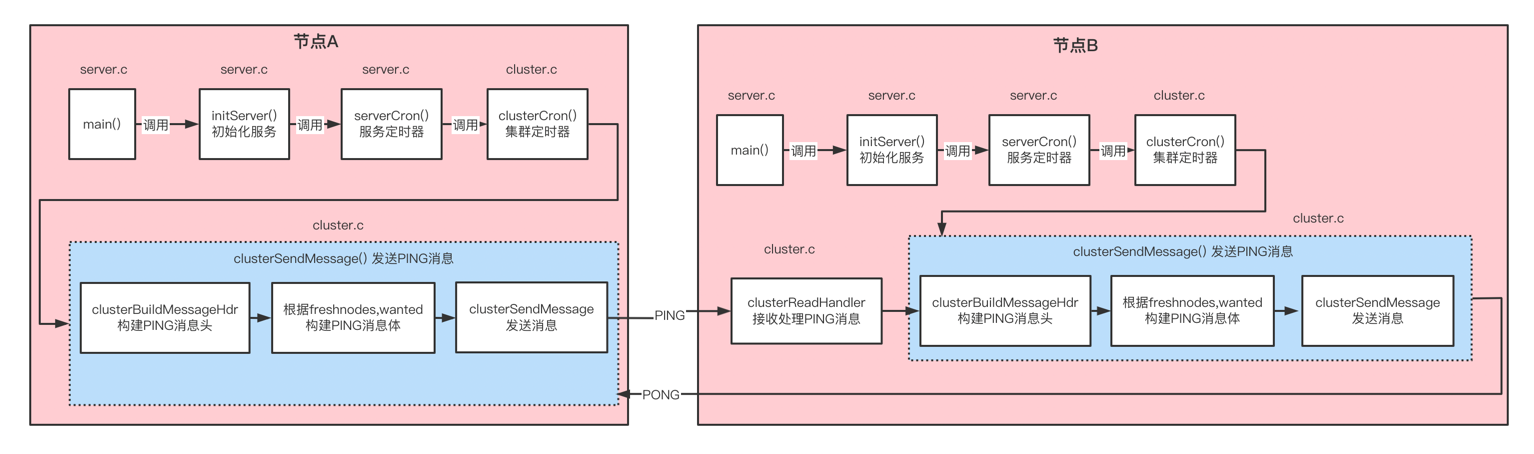
Redis Server 启动入口是 server.c 文件中的 main(),main() 函数启动后会调用 initServer()进行服务器初始化工作, initServer() 会调用 serverCron() 为 server 后台任务创建定时事件,serverCron() 会调用 clusterCron() 创建集群定时事件,源码截图如下:
发送消息
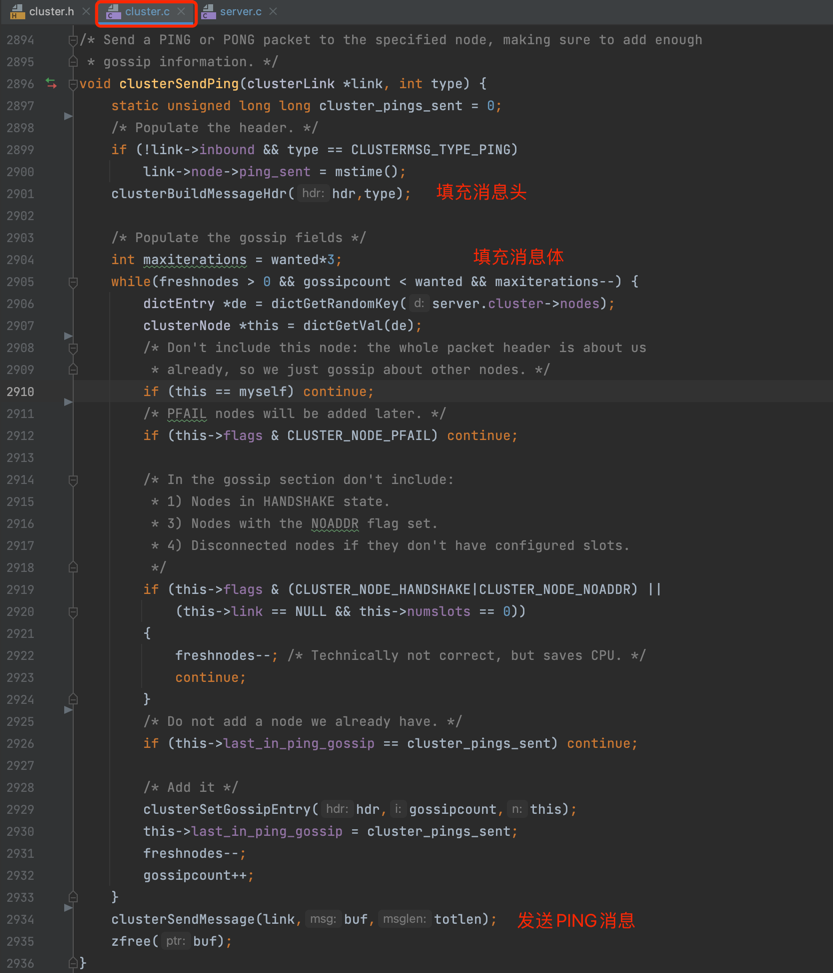
Redis是通过 clusterSendPing() 进行消息发送,clusterSendPing() 函数主要逻辑可以分成三步,调用 clusterBuildMessageHdr() 构建 PING 消息头、构建 PING 消息体和调用 clusterSendMessage() 函数发送消息,源码截图如下:
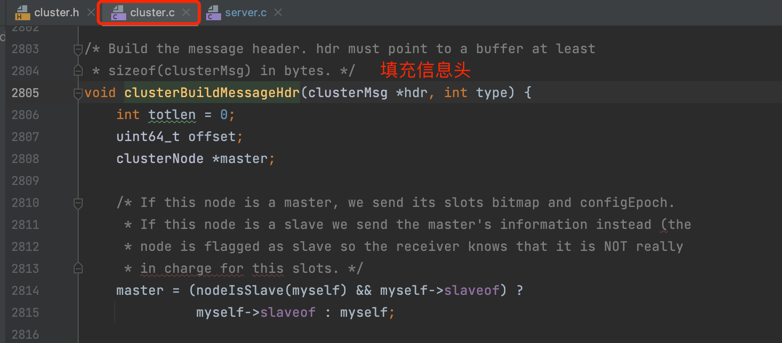
clusterBuildMessageHdr() 函数实现细节如下图:
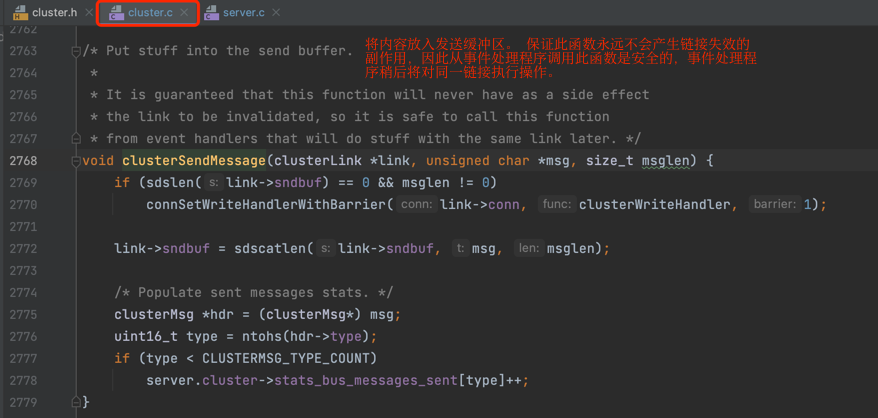
clusterSendMessage()函数实现细节如下图:
读取消息
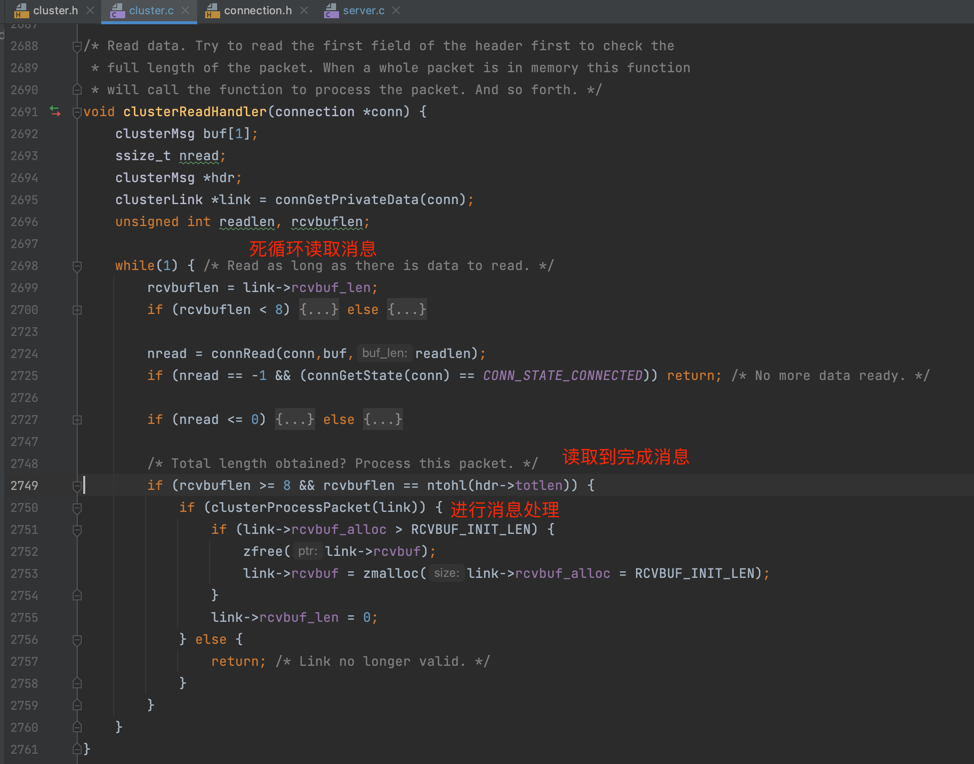
Redis是通过 clusterReadHandler() 死循环来读取消息,当读取到完整的消息时调用 clusterProcessPacket()进行消息处理,clusterProcessPacket()会按照消息的类型进行不同逻辑处理,如果为 PING或者 MEET类型,会通过 clusterSendPing() 函数响应 PONG消息,源码如下图:
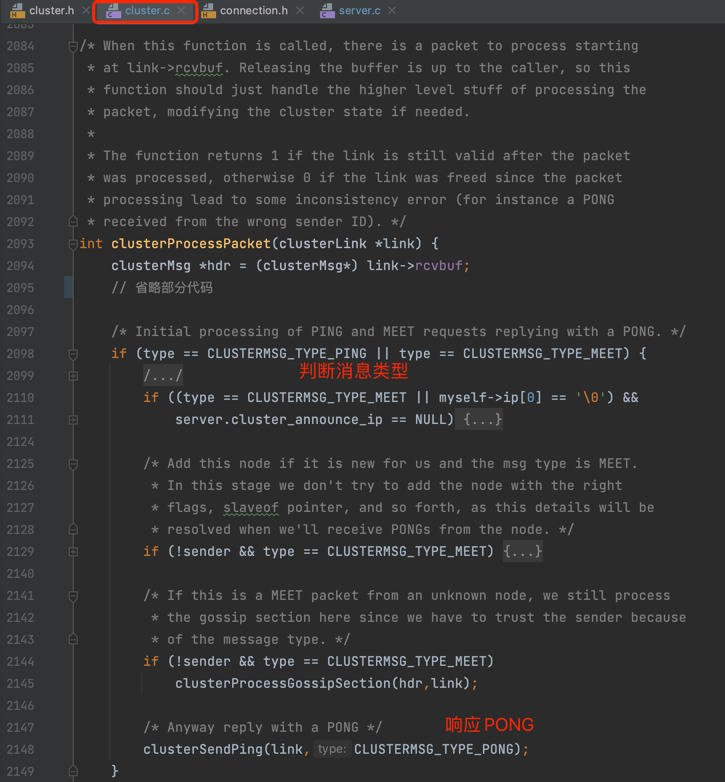
通过上面的源码分析可以看到,PING 和 PONG 消息都是通过 clusterSendPing() 函数进行发送,因此他们包含的数据也是相同的。
到此,整个执行流程分析完毕,可以总结为下图:
4. 实例展示
如下分布式场景:节点A,节点B,节点C 3个节点,每个节点上有 shard1 和 shard2 两个分片,如果在 Data 节点上存在数据缺失,我们需要如何解决?
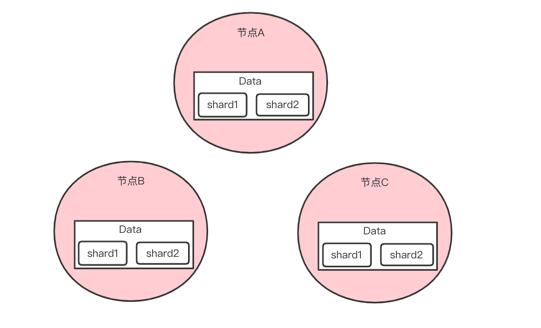
首先:我们将Data 节点上的数据缺失分为 2种情况:
节点上的 shard 丢失
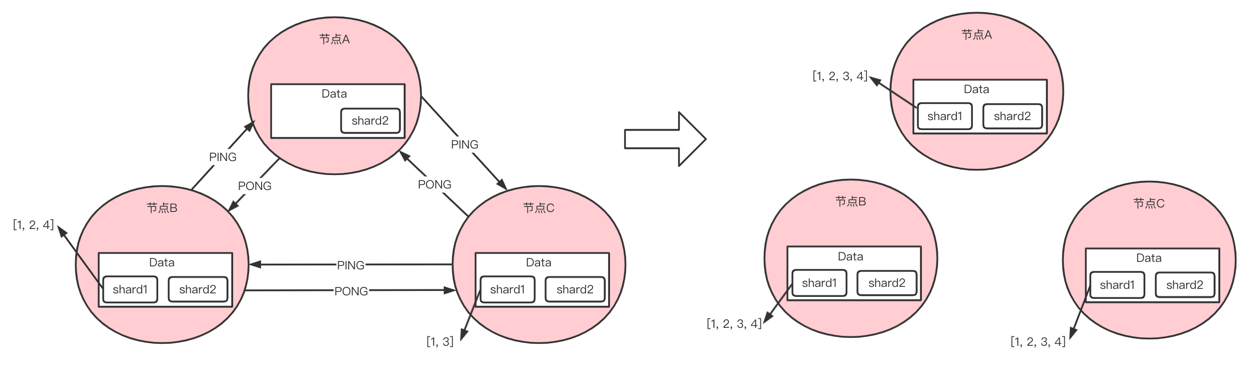
如上图:节点A 缺失 shard1分片,这种方式的数据修复比较多简单,通过 RPC 通讯,从其他节点上拷贝过来就可以了。
节点上 shard数据不一致
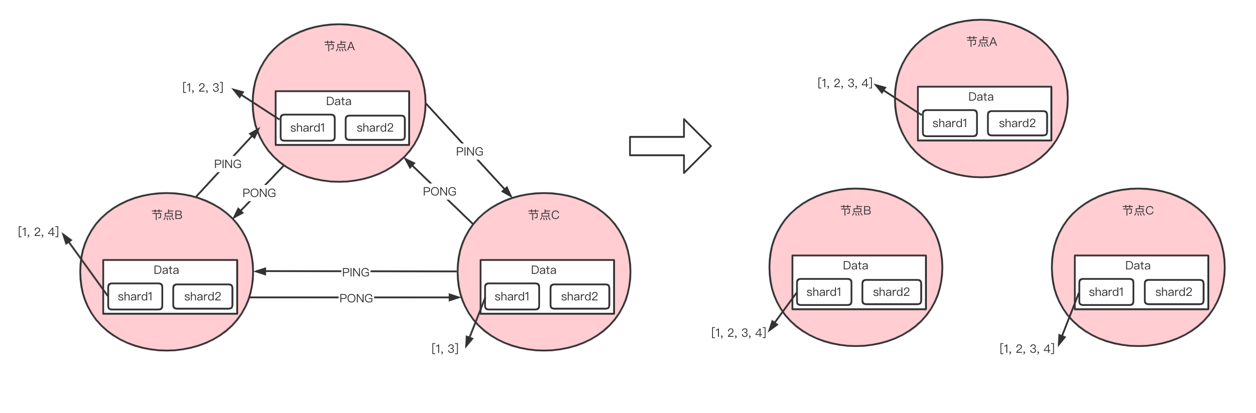
如上图:节点A,节点B,节点C 3个节点 shard1分片上的数据各不相同,这种方式的数据修复会比较麻烦一些,需要形成一个顺时针的节点数据比较和修复,这样做的好处是减少随机选择节点同步实现最终一致性带来的时间延时。
5. 总结
本文首先分析了 Gossip协议的定义和原理,然后从源码角度分析了 Gossip协议是如何保证 Redis一致性,最后,总结下本文的几个重要知识点:
- Gossip协议能实现最终一致性;
- Gossip协议主要是通过 Direct Mail、Anti-entropy 和 Rumor mongering 3种方式来实现最终一致性;
- 在 Redis Cluster集群中,采用去中心化的Gossip 协议,实现多个节点之间信息交换;
- 在 Redis Cluster集群中,Gossip协议是通过改良的 PING-PONG 方式来实现;
- 在 Redis Cluster集群中,Gossip协议是通过随机选择节点来发送信息;
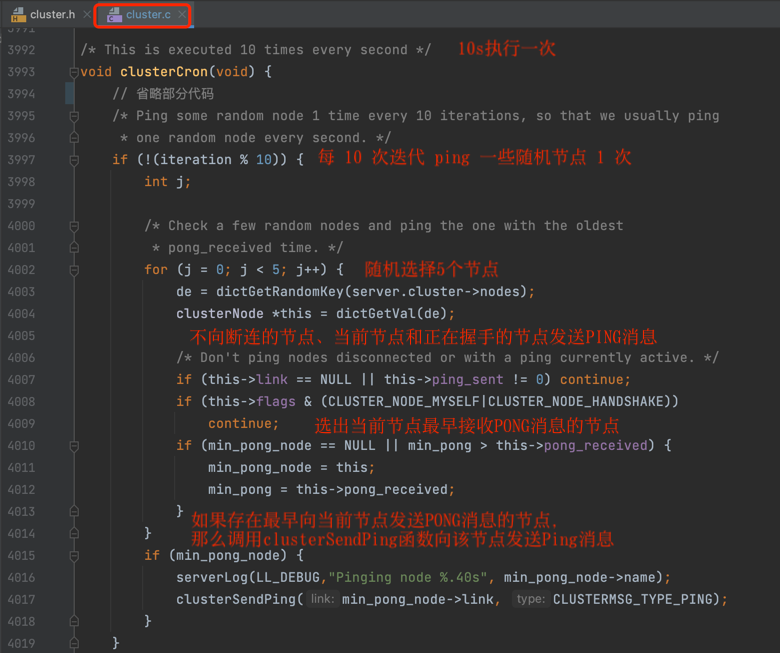
- 在 Redis Cluster集群中,Gossip协议的实现会先随机选出 5 个实例,然后从中找出最久没通信过的实例,发送 PING 消息,经过几次交换后,集群中每个实例都能拿到其它实例的状态信息;
- 在 Redis Cluster集群中,当节点状态发生变化(新实例加入、节点故障、数据迁移),也可以通过 Gossip 协议的 PING-PONG 消息完成整个集群状态在每个实例上的同步(本文并未分析,有兴趣的可以阅读源码);
6. 参考文献
EPIDEMIC ALGORITHMS FOR REPLICATED DATABASE MAINTENANCE
7. 鸣谢
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
