
如何解决MySQL 的深度分页问题?
你好,我是猿java。
在 MySQL 中,分页是一个常见的功能,但是,当出现深度分页时,因为数据库需要扫描和跳过大量记录,可能会导致性能问题,尤其是在处理大规模数据集时,那么,如何解决深度分页问题,本文我们将一起探讨,并提供多种解决方案,以提高查询性能。
1. 深度分页问题的根源
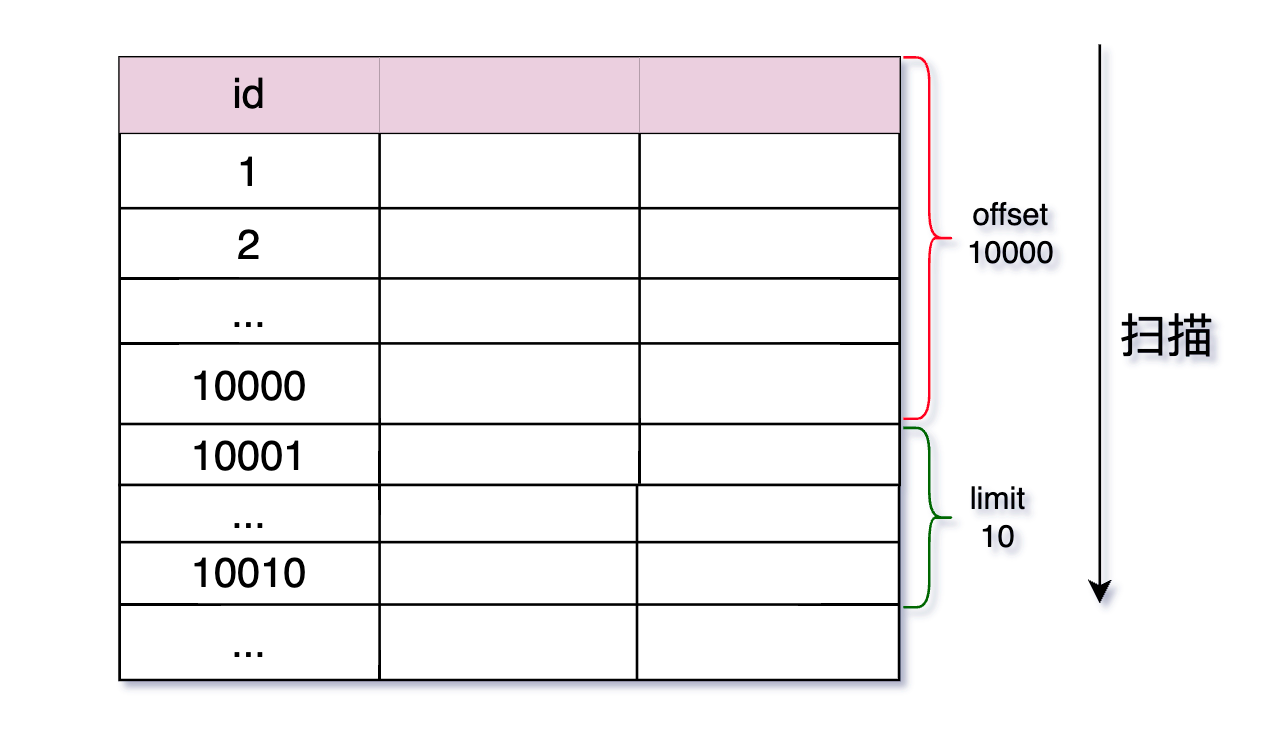
当使用 LIMIT 和 OFFSET 进行分页时,MySQL 必须扫描 OFFSET + LIMIT 行,然后丢弃前 OFFSET 行。这意味着随着分页的深入,MySQL 需要扫描的行数会越来越多,导致查询性能下降。
例如,以下查询用于获取第 10001 到第 10010 行的数据:
1 | SELECT * FROM table_name ORDER BY age LIMIT 10 OFFSET 10000; |
在这种情况下,MySQL 必须扫描 10010 行,即使只返回 10 行。这种扫描和丢弃操作会导致大量的 I/O 操作,特别是在表数据量很大的情况下。
2. 如何优化深度分页?
对于 MySQL中出现的这种深度分页问题,该如何解决呢?这里给出了几种可能的优化方案:
2.1 使用索引优化查询
确保在用于排序和过滤的列上创建适当的索引,索引可以显著减少 MySQL 需要扫描的行数。
例如,如果 where 查询语句中包含 id 列排序,确保 id 列是索引列。否则的话,可能 MySQL 会扫描所有行,从而导致性能下降。
1 | SELECT * FROM table_name ORDER BY id LIMIT 10 OFFSET 10000; |
使用索引优化查询这种方法通过避免使用 OFFSET,减少了不必要的行扫描。
2.2 使用覆盖索引
在 MySQL中尽量按需查询,如果查询只涉及少量列,可以利用覆盖索引来提高性能。覆盖索引包含查询所需的所有列,因此可以避免回表操作。
1 | -- 创建一个column1, column2的组合索引 |
上面的示例中,查询只需从索引中获取数据,而不需要访问表的数据页,因此可以避免回表操作,从而提升性能。
2.3 利用标记分页
标记分页是通过保存上一次查询的最后一个记录的标记(通常是唯一标识符)来实现的,这种方法不使用 OFFSET,而是使用 WHERE 子句来获取下一页的数据:
1 | SELECT * FROM table_name |
这种方法尤其适用于有序的、连续的分页请求。
2.4 分区表
如果数据集非常大,可以考虑使用表分区。分区可以将表分成更小的块,从而减少每次查询需要扫描的数据量。MySQL 支持多种分区方法,如范围分区、列表分区等。
如下示例:假设有一个包含销售记录的表 sales,其中有一列 sale_date,表示销售的日期。我们希望按年份对这个表进行分区,以便更高效地进行查询。
2.4.1 创建表并按范围分区
1 | CREATE TABLE sales ( |
在这个示例中,sales 表被分成三个分区:
p2021包含所有sale_date在 2021 年的记录。p2022包含所有sale_date在 2022 年的记录。p2023包含所有sale_date在 2023 年的记录。
每个分区都是独立的物理存储单元,因此查询可以只访问相关的分区。
2.4.2 插入数据
当插入数据时,MySQL 会根据 sale_date 自动将记录放入相应的分区。
1 | INSERT INTO sales (sale_id, product_id, quantity, sale_date) VALUES |
2.4.3 查询分区表
查询分区表时,MySQL 会自动确定需要访问哪些分区。例如:
1 | SELECT * FROM sales WHERE sale_date BETWEEN '2022-01-01' AND '2022-12-31'; |
在这个查询中,MySQL 只会访问 p2022 分区,从而提高查询性能。
2.4.4 其他分区类型
除了范围分区(RANGE),MySQL 还支持其他几种分区类型,包括:
- 列表分区(LIST):根据离散值列表进行分区。
- 哈希分区(HASH):使用哈希函数将数据分布到多个分区。
- 键分区(KEY):类似于哈希分区,但使用 MySQL 的内部哈希算法。
- 线性哈希分区(LINEAR HASH):一种特殊的哈希分区,适用于特定的负载和数据分布。
2.5 缓存结果
如果分页查询的结果不会频繁变化,可以考虑缓存查询结果。缓存可以显著减少数据库的负载,尤其是在高并发的场景下。
2.6 使用外部搜索引擎
对于特别复杂或数据量巨大的场景,可以考虑使用外部搜索引擎,如 Elasticsearch 或 Solr。这些工具专为处理大数据集和复杂查询而设计,通常比传统数据库更高效。
3. 实践中的注意事项
合理选择分页大小:分页大小直接影响查询性能和用户体验。较小的分页大小可以减少每次查询的负担,但会增加分页请求的次数。选择合适的分页大小需要权衡这两者的关系。
监控和分析查询性能:使用 MySQL 的性能监控工具(如
EXPLAIN和慢查询日志)来分析查询的执行计划和性能瓶颈。考虑用户体验:在某些情况下,用户可能并不需要非常精确的分页数据。可以考虑使用“加载更多”按钮或无限滚动来替代传统分页。
4. 总结
本文,我们分析了 MySQL 的深度分页问题以及解决方案。对于 MySQL 中的深度分页,我们可以通过合理的优化策略来提高查询效率。具体选用什么方案,我们需要具体场景具体分析,但是核心还是在于理解数据库的工作原理,利用索引、优化查询策略、使用标记分页、分区表、缓存结果等些优化技术。
5. 学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
